Please note that this Installation Guide is only applicable for customers using Scheer PAS BRIDGE.
Customers using Scheer PAS BPaaS will not have to install the application on their own.
Overview on the Components of Process Mining
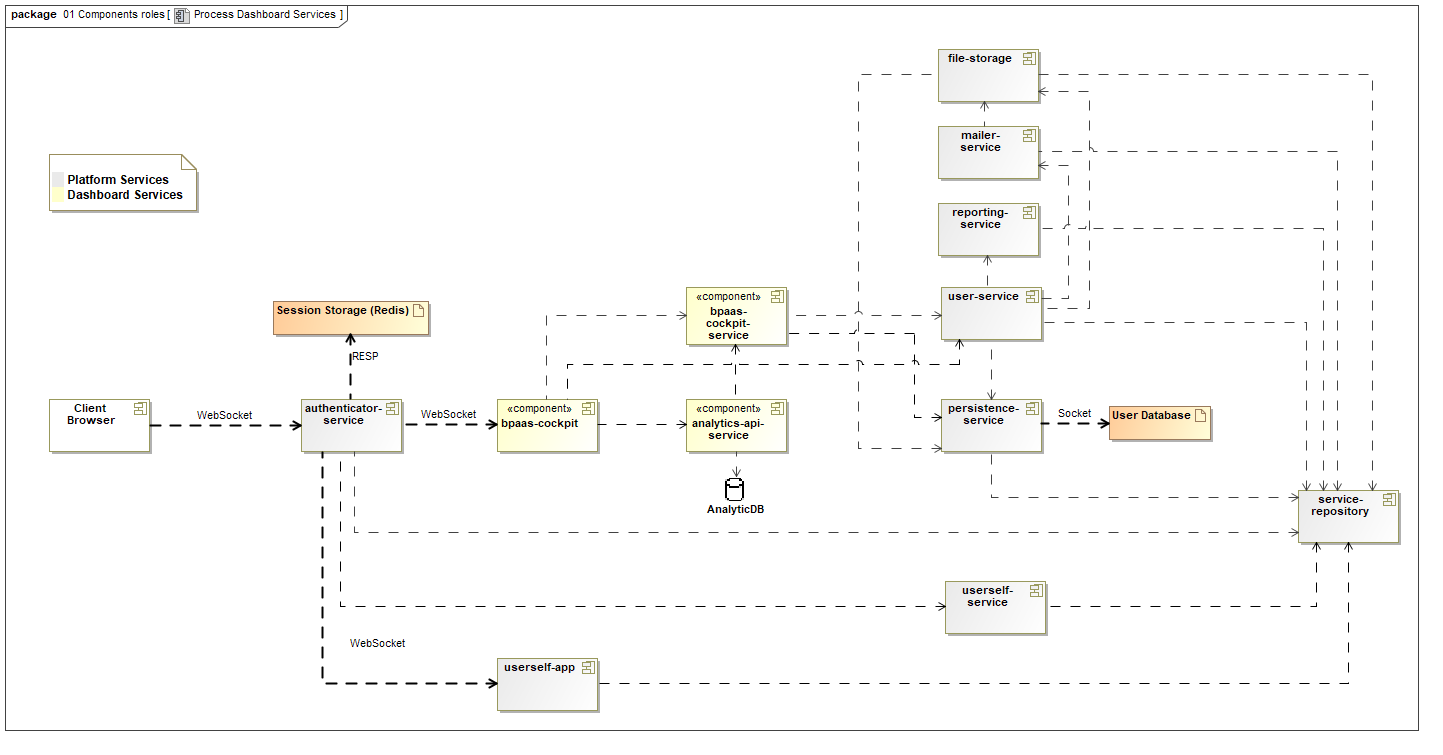
Have a look at the figures below to get a technical overview on the components of Scheer PAS Process Mining.
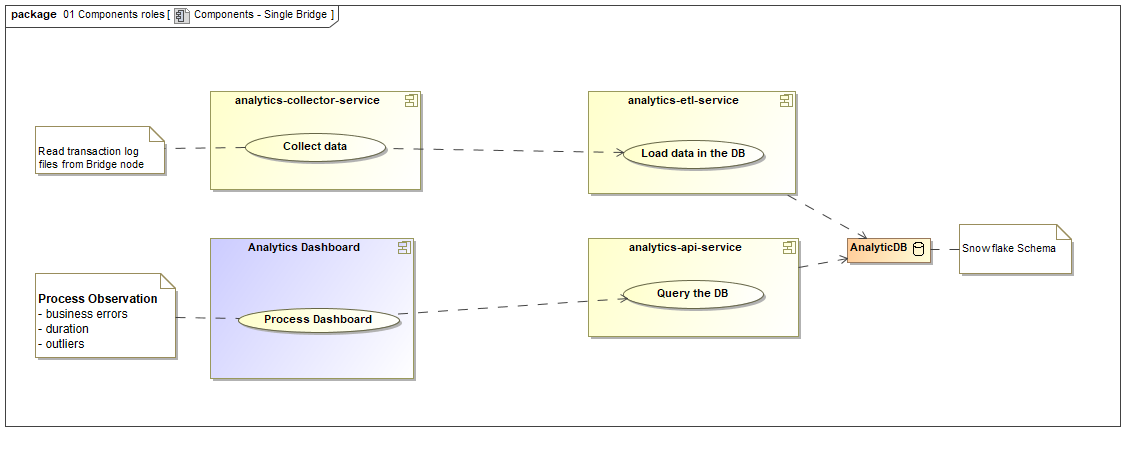
Scenario 1: Single BRIDGE Installation
If you have set up one single BRIDGE installation on a machine, the full stack of Process Mining services needs to be deployed and executed on that machine.
Figure: Technical Overview on the Components of Process Mining (Scenario 1)
Scenario 2: Distributed BRIDGE Installations
If you have set up BRIDGE installations on multiple nodes to distribute the services, you might want to collect and analyze data from multiple nodes. In that case it is not necessary to deploy the full stack of Process Mining services to each BRIDGE installation. You need to setup file shares to let the analytics-collector-service access the BRIDGE data directories of each node. Therefore, only one node is needed to run the full stack of Process Mining services.
Figure: Technical Overview on the Components of Process Mining (Scenario 2)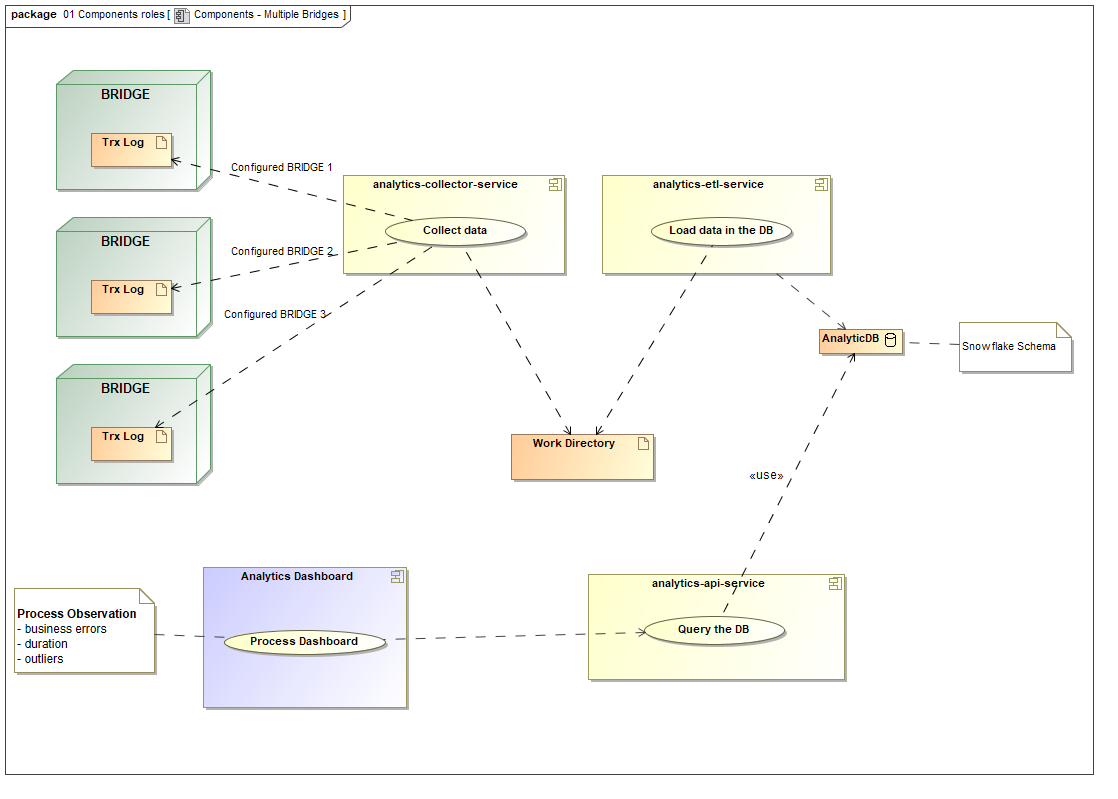
Overview on the Installation Process
To install Scheer PAS Process Mining, you need to got through the following steps:
- Setup the database used by the Process Mining services.
The Process Mining services rely on analytical data that has been collected and stored in a database.
For a description on how to setup the database for the use of the Process Mining services, refer to Setting up the Database for Process Mining. - Deploy the services that will collect, extract and query the analytical data.
The analytical data Process Mining relies on have to be collected and extracted to the analytical database. The services provide an interface to inspect the collected Process Mining data.
For a description on how to deploy the data services, refer to Deploying the Services. - Connect the data collection services to the database.
To connect the deployed services from step 2 to the database configured in step 1, you need to adjust some Node.js settings to match your configuration as described in Configuring the Process Mining Services. - Start the services.
Start analytics-etl-service first. Once it initialized the Analytic Database, start the other services.Please note that prior to version 19.2 the services must be started in the following order:
service-repository
persistent-service
file-storage
reporting-service
user-service
mailer-service
then all other services
- Use the Scheer PAS Administration to create Process Mining users.
In order to use Process Mining, assign the necessary profiles to the system users. For further information about the needed profiles and how to assign them, consult the Administration Guide. See page Configuring the Platform Services for further information about the composition of the Scheer PAS Administration URL.
Updating the Dashboards
Generally, you can just upload the latest service repository to update the Process Mining services. However, with updating analytics-etl-service there are some restrictions and you have to follow the procedure described in Updating the Services.
Overview
Content Tools